
Small String Optimization Part 1
Exploring A Basic Implementation in C++


The string class is a fundamental component in C++ development and many compilers have introduced optimizations to enhance its efficiency. In this article, we aim to create a basic implementation of one of the most common optimizations, known as Small String Optimization (SSO).
The SSO concepts explored in this article are inspired by Nicholas Ormrod’s talk on “The strange details of std::string at Facebook”. While these ideas serve as our source of inspiration, the implementations we showcase here are entirely our own.
For the full source code, you can refer to the UTD GitHub repository.
Why SSO?
In C++, strings frequently utilize dynamic memory allocation because their length can vary, making it challenging to determine the exact memory allocation needed during compile-time. However, for short strings, this can lead to unnecessary overhead in terms of memory usage and performance.
The concept of SSO addresses this issue by allowing the string to store its data directly within the string object itself, eliminating the need for dynamic allocation for short strings. This optimization is particularly valuable for scenarios where many short strings are used, as it significantly reduces memory fragmentation and improves overall performance.
A simple string class
Before we look at making small strings work better, let's first think about how to create a basic string. A string can be thought of as just a collection of consecutive characters. We can dynamically allocate the memory for the number of characters and store the head of the memory block in a char pointer. This is how strings are handled in C, which is why const char pointers are also called C-strings. Adding a constructor to initialise from a string literal and destructor, our basic string class might look something like this:
class basic_string {
char* data;
}
...
basic_string::basic_string(const char* s) {
size_t size = strlen(s);
data = new char[size + 1];
}
basic_string::~basic_string() {
delete[] data;
}As it is now, using this basic_string class would not have much benefit over simply using a C-string besides having automatic memory freeing on destruction. A big reason for using string classes is to have access to helpful functions that make working with strings easier. For the purpose of this article, we will be looking at implementing 3 of the most commonly used functions in our string implementations:*
c_str()— returns the string data as a C-string for easy compatibility with C librariessize()— returns the length of the stringreserve()— dynamically allocate a larger block of memory than the current number of characters in the string. This prevents the need for dynamic allocation each time the string changes in length.
* This excludes default/copy constructors, move semantics, operator functions and other helpful string functions. For the full implementation, please refer to the source code.
For our basic_string class, implementing c_str() is simple, as we just have to return the data variable.
For size() we could call strlen() each time like we do in the constructor, to calculate the size when it is needed. However, strlen() has linear time complexity, meaning the time taken for it to execute increases linearly with the size of the string. Instead, we can have a dedicated member variable to make size() a constant-time read operation.
Lastly, for reserve() we need to keep track of the current amount of allocated memory, since this can be different from the current string length. For this, we use a member variable called capacity.
class basic_string {
char* data;
size_t size;
size_t capacity;
}
...
basic_string::basic_string(const char* s) {
size = capacity = strlen(s);
data = new char[size + 1];
strcpy(data, s);
}
basic_string::~basic_string() {
delete[] data;
}
const char* basic_string::c_str() const { return data; }
size_t basic_string::size() const { return size; }
void basic_string::reserve(size_t new_capacity) {
if (new_capacity <= capacity) return;
char* new_data = new char[new_capacity];
strcpy(new_data, data);
delete[] data;
data = new_data;
capacity = new_capacity;
}Now we have a working implementation of a simple string class. When we need to create a string, we allocate memory dynamically to accommodate its content. If we anticipate the need for a larger string, we can reserve a larger block of memory using the reserve() function, thereby minimizing the frequency of dynamic allocations. However, there are definitely opportunities to further improve the performance of our simple string.
Improving on basic_string
Although strings can theoretically expand infinitely (up to the maximum value of our size variable), it is important to note that in practice, working with extremely long strings is uncommon. Typically, strings tend to be relatively short. For instance, when dealing with English words, string lengths are usually within 15 characters. With this in mind, what if we could store the character data of strings within this 15 character limit in-situ within the string class itself? This would allow us to make use of stack memory which is significantly faster than using dynamic allocation.
How can we modify the basic_string class we created above to include this optimization? First, let us create a new class and call it string32 (the object size is 32 bytes on a 64-bit system) with the same member variables as basic_string, but with an additional 8 bytes of character buffer.
class string32 {
char* data;
size_t size;
size_t capacity;
char buffer[8];
}For large strings, string32 can mirror the functionality of the basic_string class, by dynamically allocating memory that data points to, while tracking the size and capacity in the respective member variables.
However, for small strings, we can store the character data directly within the string object. As it stands, we already possess 8 bytes of buffer data that can be employed for this purpose. Moreover, a capacity variable is actually not needed for small strings, so we can repurpose this 8 bytes in this variable to also store character data instead. If we define a small string as one whose character data can fit within the space of both capacity and the buffer, we can ensure that the capacity of such small strings consistently remains at 15 (accounting for the null terminator).
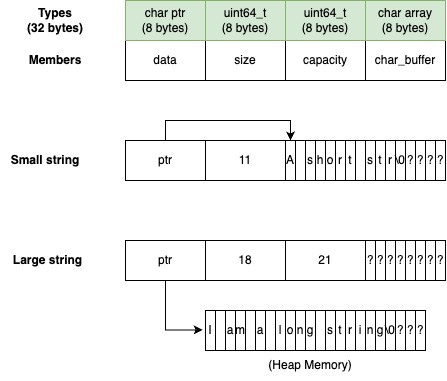
However, there is one major problem with this implementation - how will we know whether the string is a small or large string?
To determine whether a string is small or large, we must embed a boolean flag within the string's data structure. However, choosing where to store this flag presents a design challenge. The buffer variable seems like a suitable candidate because it remains unused in large strings. Yet, in small strings, it serves as a container for character data. One option is to reserve the last byte of buffer for the flag. However, this approach would reduce the small string's capacity by one character. The question then arises: can we find a way to embed the flag without diminishing the small string's capacity?
In Nicholas’ talk, he shared how Andrei Alexandrescu was able to find a way to store the flag value without compromising on the small string capacity. Andrei's insight was that, for small strings, the last byte is consistently unused except when the size matches the maximum capacity of a small string. In this unique scenario, the last byte coincidentally holds the null terminator value (0). Consequently, it's possible to utilize the last byte for storing string flags, provided that these flags are always set to 0 for small strings.
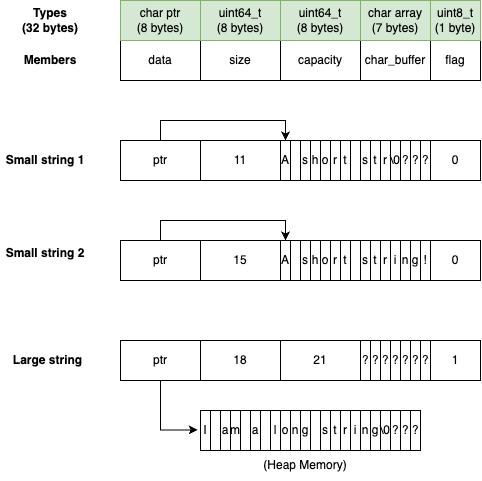
Using the last byte, we can add the functions isLarge() and setLarge() to get and set the current string type.
class string32 {
char* data;
size_t size;
size_t capacity;
char buffer[7];
unsigned int flags;
}
...
static constexpr unsigned int LARGE_STRING_FLAG { 1 };
boolean string32::isLarge() const {
return flags & LARGE_STRING_FLAG;
}
void string32::setLarge() {
flags |= LARGE_STRING_FLAG;
}Adding the member functions
First, let’s add our string literal constructor. If the string size exceeds the small string max capacity, then initialisation is the same as basic_string with only one additional operation to set the string flag to large. Otherwise if the string size can fit in the in-situ memory, dynamic allocation is not needed. Instead, we point data to the head of capacity before copying in the string data. We also have to set flags to 0 since this is a small string:
class string32 {
char* data;
size_t size;
size_t capacity;
char buffer[7];
unsigned int flags;
}
...
// 15 for 64-bit system
static constexpr int SMALL_STRING_CAPACITY { sizeof(size_t) + 7 };
string32::string32(const char* s) {
size = strlen(s);
if (size > SMALL_STRING_CAPACITY) {
capacity = size;
data = new char[size + 1];
setLarge();
} else {
data = (char*) &capacity;
flags = 0;
}
strcpy(data, s);
}To implement c_str() and size(), we can mirror the behavior of basic_string by simply returning their member variable values. For reserve(), we introduce an extra check to prevent deallocating memory when the string previously used in-situ storage. Additionally, we will have to set the string flag as large at the end of the function, because dynamic allocation is only required for large strings.
const char* string32::c_str() const { return data; }
size_t string32::size() const { return size; }
void string32::reserve(size_t new_capacity) {
bool isLarge = isLarge();
size_t curr_capacity = isLarge ? capacity : SMALL_STRING_CAPACITY;
if (new_capacity <= curr_capacity) return;
char* new_data = new char[new_capacity];
strcpy(new_data, data);
if (isLarge)
delete[] data;
data = new_data;
capacity = new_capacity;
setLarge();
}And there you have it! We've successfully integrated a simple example of SSO into our string32 class. For strings of 15 characters or less, no dynamic allocation is needed, resulting in significantly faster object initialization and string concatenation, as long as the total size remains under 15. While strings larger than 15 characters are still supported, they will utilize the traditional dynamic allocation method.
What’s next?
The whole basis of SSO relies on the assumption that stack memory is faster than dynamic allocation. In Part 2 of this article we run benchmark tests to visualise how much of a benefit SSO really provides. In that section we also explore how to further improve our current SSO implementation and how it stands up against the most popular std::string implementations.
 | A guest post by
|